
Revolut on the Inference Frontier

Long story short
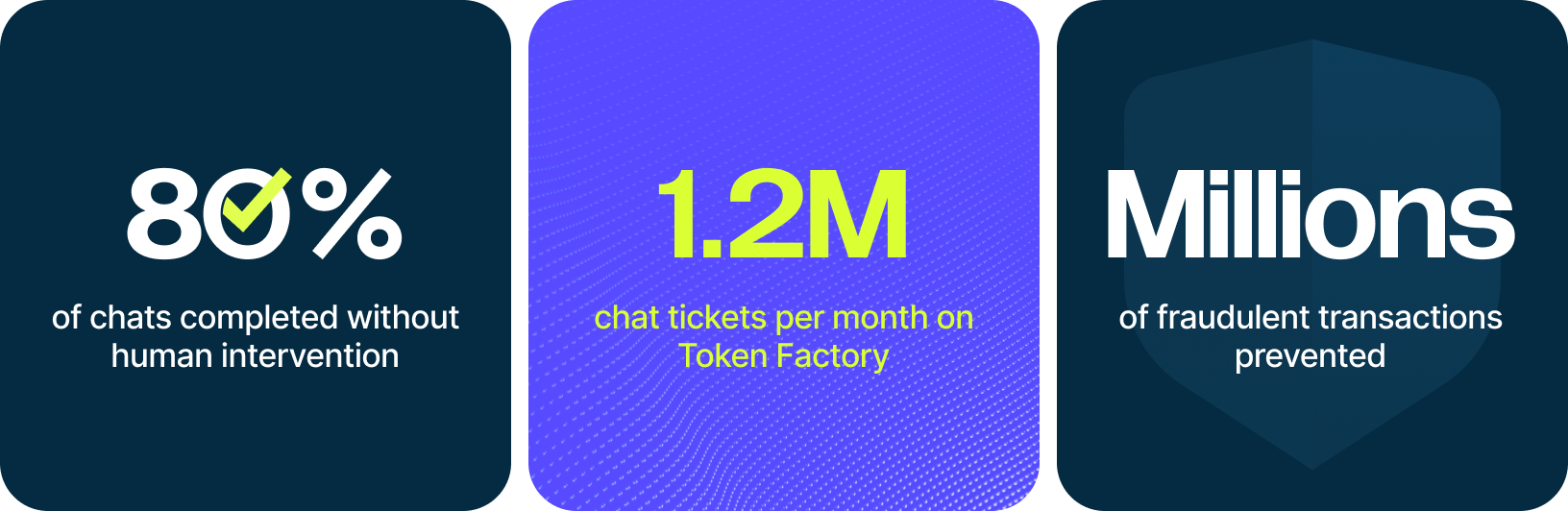
Revolut rebuilt its platform around AI to support growth from 30 to 70 million users in three years. Behavioral data from 40 billion events powers shared embeddings used across fraud detection, credit scoring and transaction prediction. Running on more than 200 NVIDIA H100 GPUs on Nebius AI Cloud, Revolut uses Nebius Token Factory to power FinCrime agents preventing millions of fraudulent transactions and a chat system handling up to 1.2 million support tickets each month.
![]()
Revolut is a London-founded global fintech company that offers app-based banking and financial services including payments, spending, savings, investing, foreign exchange and business accounts. It has grown rapidly to more than 70 million customers worldwide and operates in 40 markets, with ambitions to keep expanding internationally. The company reported record 2024 results, including £3.1 billion in revenue and £790 million in net profit, reflecting both strong customer growth and a broadening product mix.
In 2026, Revolut runs on code the way banks once ran on real estate, building digital systems of trust, governance and distribution at global scale. From 38 million users in mid-2023, to more than 70 million in early 2026, Revolut is one of the fastest growing and respected financial institutions in the world with a Trustpilot rating of 4.7 stars from over 350k users. Behind that growth is a deliberate, multi-year investment in AI powered products and systems.
Two years ago, Revolut launched the first version of its support chatbot using external LLM providers. Since then, the system has expanded to 100 percent coverage with roughly 80 percent of chats successfully resolved without escalation to a human agent. Along the way, the team experimented with multiple frontier model providers. Closed, foundation models offered rapid experimentation for broad tasks, but over time, tasks became more specific and scale added complexity. The difficult problems were no longer centered on improving model quality, but orchestration, evaluation, observability, latency, reliability and controls. As Pavel Nesterov, Executive Director of AI at Revolut, notes, careful data fetching and context engineering often matter more in production than heavy RAG patterns. At the same time, he has consistently backed fine-tuning and in-house models as the long-term direction, especially for highly specific, high-scale and strategically important use cases. He credits his team, and his AI partners for moving quickly, and with discipline to build reliable products that immediately add value to the customer experience. The same discipline now shapes every major AI initiative inside the company.

Rodolphe Cambier sits at the center of that evolution, as a member of Val Riabtsev’s Platform team, leading one of Revolut’s major AI workstreams. As Lead Data Scientist for AI Automation in the FinCrime division, he and his team built and oversee 9 AI agents performing financial crime and anti-money laundering risk assessments every month, preventing millions of fraudulent transactions per month. These agents screen customers against real-time sanctions lists, analyze customer transaction histories and support web search and customer contact. As one example of a re-engineered process, the money laundering investigations that historically required up to six human touchpoints are now close to only one, leading to faster investigations with human analysts able to focus on the areas of highest risk with clear referenceable data.

FinCrime AI Agents are analysing two million tasks per month from roughly 700k unique customers. Human oversight remains central. Agents surface structured evidence, intermediate reasoning artifacts and reproducible decision paths, enabling replay and audits for any stage. Accuracy has improved while reducing customer friction.
The mission sounds simple but is complex to achieve. Keep growth fast, compliance airtight and a human ultimately accountable for every customer-impacting decision. They generate alerts for suspicious activity, monitor and act against risky activity, ensure details match when onboarding a customer and orchestrate complex workflows. The system must be explainable enough that a leader can step in, review a case and understand exactly why a decision occurred. Achieving that required a full rebuild.
“We needed to redesign the process for both AI and human oversight, ” Rodolphe explains. Customer input often arrives asynchronously, sometimes over weeks. The new system had to support both customers and investigators without introducing bottlenecks. The result is a cleaner, observable and more resilient workflow.
At first, FinCrime agents relied on proprietary, frontier models through Revolut’s internal LLM gateway. The team expected complex risk assessment tasks to be better served by state-of-the-art proprietary models, with the assumption that prices would decrease over time. As monitoring expanded across the customer journey, token usage rose, then margins tightened and costs moved in the wrong direction.
That pressure reframed the architecture. The team isolated token-heavy reasoning steps and began to evaluate open models on Nebius Token Factory. DeepSeek R1 lacked sufficient context capacity. Kimi K2 introduced quota instability under load, so the team pivoted to Kimi K2.5 which demonstrated strong reasoning at roughly one third the cost out of the box, with a 256k context window. Then it was load-stabilized through dedicated endpoints. The architecture was updated with staged evaluations, where structured features narrowed scope before large-context reasoning was invoked which passed large blocks of data through steps without consuming tokens. “The same way a human can pass a book without reading it entirely, we design our agents to be able to manipulate data without putting it in full context, ” Rodolphe says.
Underpinning these agents is the Revolut FinCrime AI Agents Platform, which has been built to maximize observability, auditability, governance and controls. FinCrime Product teams can design and configure end-to-end AI agents in a no-code interface offering inspection of orchestrator prompts, connected tools, model choices, memory configuration and safely creating new versions. “The FinCrime AI agents platform not only allows us to scale fast, but also ensures maximum observability, controls and governance around the AI agents we deploy”, says Val Riabtsev, Head of Platforms at Revolut FinCrime division.
Transforming the data science loop:

Today, the team can load new datasets, experiment and deploy in one click, a significant departure from scattered SQL scripts and manually deploying APIs. Across workloads, Revolut now runs training and inference on more than 200 NVIDIA H100 GPUs through the Nebius AI Cloud, connected through high-bandwidth Infiniband to support large-scale GPU synchronization across nodes. Data preparation and feature engineering on billions of records is accelerated by NVIDIA cuDF, while core deep learning workloads are accelerated with cuDDN, providing highly optimized GPU kernels for core neural network operations.
That same infrastructure helps to power Revolut’s Chat Orchestrator, which handles up to 1.2 million chat tickets per month and will soon hit ninety percent of chats resolved without human escalation. Custom weights are deployed directly into Nebius Token Factory and scaled across production traffic. As the system matured, the team worked with Nebius solutions architects to improve orchestration, latency, cost and stability. Revolut treats inference quality and response time as core product features. Dedicated endpoints and tight observability loops ensure the chatbot behaves predictably under load while maintaining high retention. “The Revolut team combines enterprise-grade discipline with the agility of a modern tech company. The strong engineering synergy between Nebius and Revolut has been a core driver of this successful partnership, ” says Hasan Colak, Account Executive from Nebius.
Let us build pipelines of the same complexity for you

Revolut is also building a foundational, event-based transaction model called PRAGMA trained on years of behavioral data spanning more than 40 billion events from 25 million users. By tokenizing tabular financial data and applying LLM-style training methodology, the team created shared embeddings that are reusable across domains such as financial crime, product cross-sell and credit risk assessment. They have fine-tuned 3 PRAGMA models, with 10M, 100M and 1B parameters optimized for tasks from real-time low-latency in fraud detection to precision requirements where latency is less important. Trained on a dedicated cluster of 64 NVIDIA H100 GPUs, using solutions like NVIDIA cuDF and NVIDIA NEMOTRON models running on Nebius AI Cloud, PRAGMA replaces fragmented domain-specific models with a unified baseline. LoRA adaptation fine-tune performance on 1-2% of total parameters to reduce costs without rebuilding from scratch, reducing retraining cycles and accelerating deployment across use cases. Anton Repushko, who’s leading the research, described the biggest win for his team as the Nebius experts. “They operated as both owners and managers across the full Nebius stack providing support for training our transaction model.” The team has achieved compelling enhancements including 3x faster pre-training efficiency, and 21% increase in precision for fraud detection tasks.
Across many scenarios, Nebius Token Factory provides rapid access to the latest models, open-source flexibility and reliable scale when our traffic spikes. Dedicated endpoints improved predictability. “We found success by rebuilding the process around both agents and humans from first principles. You can’t simply add AI to an existing human-based process. After the system is right, the move to open-source can lead to huge savings and more control. The Nebius team has been super responsive. Token Factory just works, especially if you need to scale up quickly, ” says Rodolphe.
Nebius now supports six core use cases at Revolut, including FinCrime automation, cross-sell optimization, chat orchestration, text-to-image card customization, retraining lighter open-source models and foundational transaction model training. Inference is no longer experimental, but a core business lever and a board-level performance indicator. The team expects the ability to replay decisions, swap agents and understand outcomes in real time. As Revolut begins piloting an end-to-end in-house voice pipeline for a subset of customers, latency and reliability standards continue to rise. Customer trust, regulatory exposure, growth and cost discipline all depend on it.
Rodolphe views the next phase with curiosity and optimism. Agentic systems improve weekly, and model response will feel increasingly instant. The team studies benchmarks, tests new releases and builds systems capable of hot-swapping models without disrupting traffic. AI reduces friction and sharpens judgment while humans remain accountable for final outcomes, and partners like Nebius remain critical to intelligent scaling.
Revolut’s bet in 2026 centers on more compute for larger, more capable systems with real world pressure to perform. Open-source models are one way to achieve 10x cost efficiency, while a full-stack architecture supports orchestration, evaluation, observability and reliability. When inference and training become a board-level KPI, infrastructure becomes the foundation.
More exciting stories

vLLM
vLLM
Using Nebius’ infrastructure, vLLM — a leading open-source LLM inference framework — is testing and optimizing their inference capabilities in different conditions, enabling high-performance, low-cost model serving in production environments.

SGLang
SGLang
SGLang, a pioneering LLM inference framework, teamed up with Nebius AI Cloud to supercharge DeepSeek R1’s performance for real-world use. The SGLang team achieved a 2× boost in throughput and markedly lower latency on one node.
London Institute for Mathematical Sciences
London Institute for Mathematical Sciences
How well can LLMs abstract problem-solving rules and how to test such ability? A research by the London Institute for Mathematical Sciences, conducted using our infrastructure, helps to understand the causes of LLM imperfections.