
Building a compliance audit agent using Nebius Agents Blueprint
Building a compliance audit agent using Nebius Agents Blueprint
Most AI agents don’t fail because of the model. When you trace what actually breaks in production, it’s almost always the harness around the model: retrieval returning the wrong material, no live grounding for time-sensitive queries, inference costs that make the economics unsustainable at scale, no traceability when something goes wrong, and behavior that was never stress-tested before launch.
The model performs exactly as designed. But it reasons faithfully over a broken system.
The question worth asking today isn’t “can an agent do this task?” — a capable model usually can. It’s “what does it take to make that agent production-ready?”, meaning reliable, observable, and economically viable. This post answers the latter with a single case study run as four successive configurations of the same agent. Each configuration solved the previous bottleneck and, in doing so, exposed a more sophisticated one. That progression is the maturity curve.
The case study: building Sentinel
We built Sentinel, a regulatory compliance audit agent, on the Nebius Agents Blueprint. Its job is concrete and high-stakes: take a change in regulatory guidance, find every Standard Operating Procedure it touches across a 200-SOP corpus spanning 10 business units, classify the severity of each gap against 36 regulatory frameworks — HIPAA, SOC 2, GDPR, the EU AI Act, NIST AI RMF, and others — and file a Jira ticket for every confirmed finding.
We ran the same task through four configurations: “the FDA issued new guidance on AI-enabled medical devices in the past 12 months; identify every impacted SOP, classify severity, generate remediation recommendations, and create Jira tickets for all high-severity findings”. We used the same corpus, same prompts, and same retrieval index each time.
 Figure 1. One agent, four generations. The same audit task is run through Prototype, Grounded, Optimized, and Production configurations — the maturity curve made selectable.
Figure 1. One agent, four generations. The same audit task is run through Prototype, Grounded, Optimized, and Production configurations — the maturity curve made selectable.
Two datasets inform this post. The FDA audit task numbers come from live runs with real LangSmith-instrumented traces. The 120-task benchmark numbers come from a fixed evaluation dataset with known ground truth, used to measure quality consistently across all four configurations.
The maturity curve, one generation at a time
| Generation | Configuration | Time | Cost | Tickets | Solved → Exposed |
|---|---|---|---|---|---|
| 1. Prototype | GPT-5.5 + Pinecone | 29.9 min | $469.99 | 5 | Task completion → Freshness & accruacy |
| 2. Grounded | GPT-5.5 + Pinecone + Tavily | 30.7 min | $657.19 | 12 | Freshness & accuracy → Inference economics and scope |
| 3. Optimized | DeepSeek-V4-Pro on Nebius Token Factory + Pinecone + Tavily | 53.9 min | $34.63 | 14 | Economics (~19× cheaper) and scope → Runtime and trust |
| 4. Production | Nemotron-Ultra on Nebius Token Factory + Pinecone + Tavily + LangSmith + Snowglobe | 12.6 min | $23.59 | 10 | Observability & simulation → Operating at scale |
FDA audit task — live runs, unmocked. Cost and runtime from LangSmith-instrumented traces.
No configuration failed. Each one solved a real bottleneck (freshness, economics, governance, or observability), completed the task, and produced output you could act on. What changed at each step was the ceiling: what the system couldn’t do that only became visible once the previous limitation was cleared.
Generation 1 — Prototype: it works, and that’s the trap
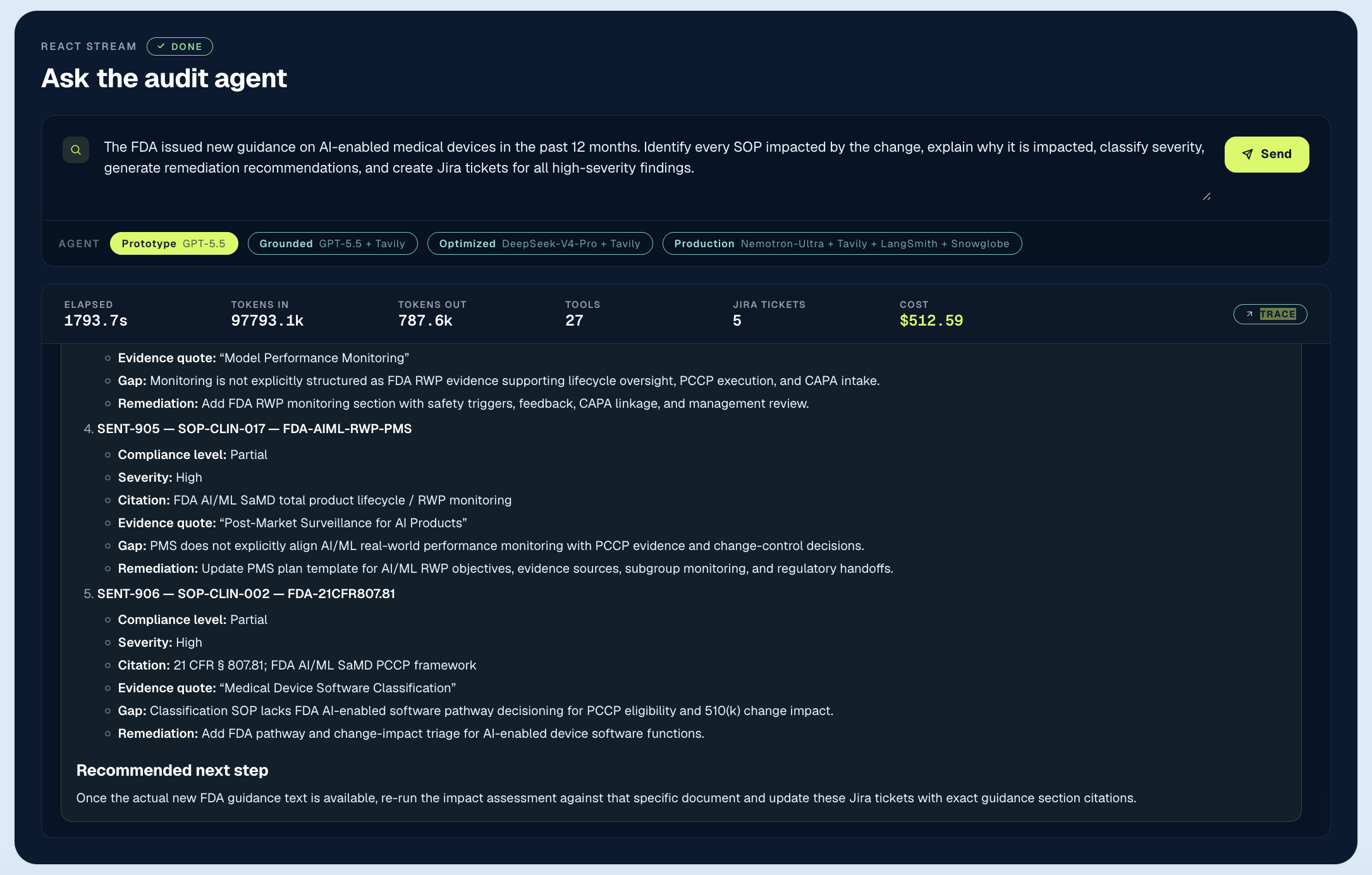
The prototype is the configuration most teams ship: a frontier model (GPT-5.5) wired to vector retrieval over a static corpus, with no live grounding. It works. It reasons over SOPs, produces findings with citations, and files tickets. But it has no access to current FDA guidance beyond what was in the index at its last crawl, with no live source feeding it. It identified 11 impacted SOPs and filed 5 high-severity tickets. Findings were real but with narrow scope, weak prioritization, meaning the goal outcome was only partially achieved.
The bill for one audit was $469.99: frontier model pricing for a system that couldn’t ground itself in current information or decide what mattered most. This is the prototype ceiling, and it’s invisible in a demo because the output looks structured until you check whether it’s actually answering the right question.
Generation 2 — Grounded: closing the freshness gap
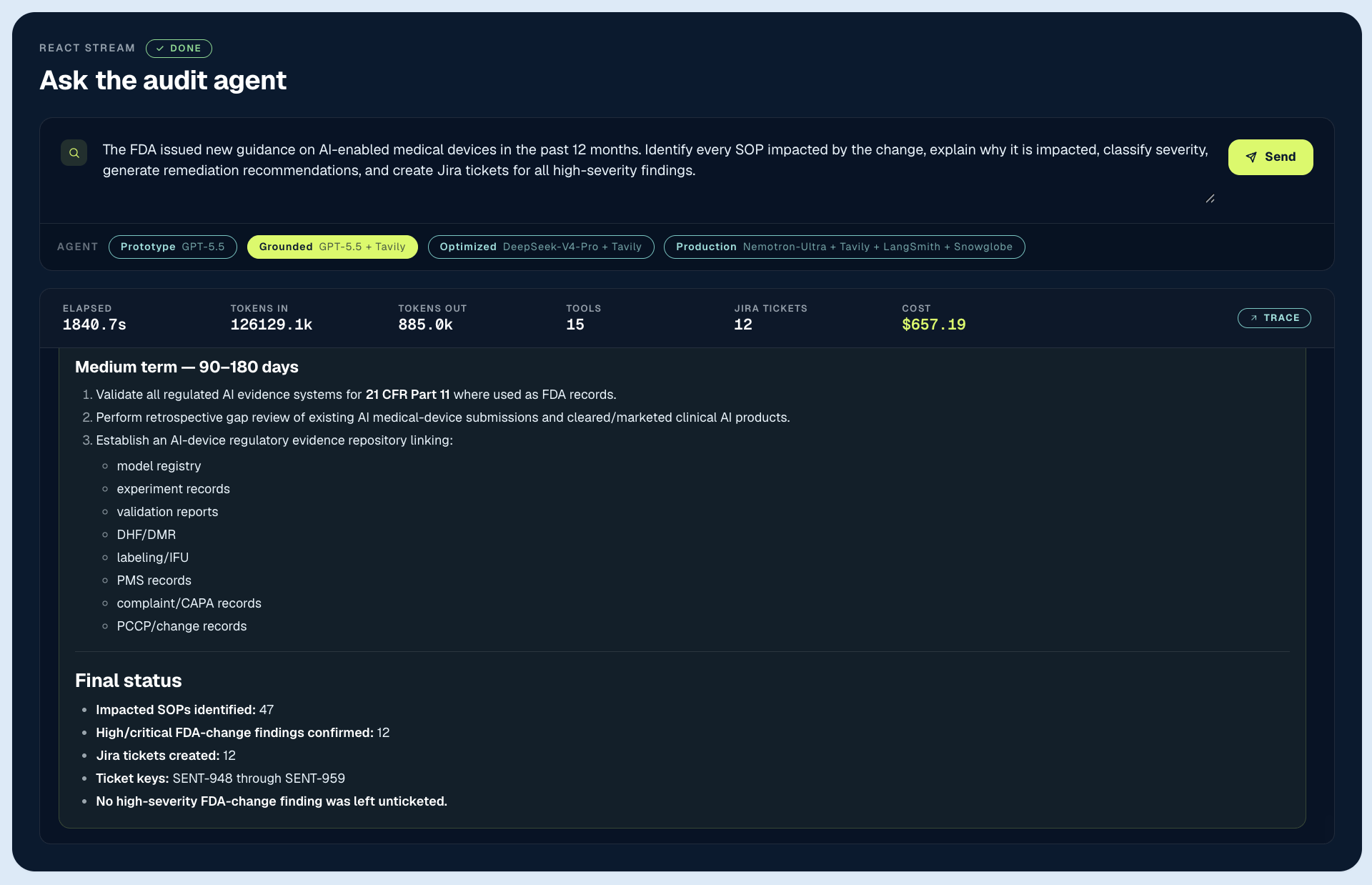
A knowledge base indexed last month is wrong today. A compliance audit that turns on recent FDA guidance cannot answer reliably from a static chunk. Adding Tavily for live web grounding changed the picture dramatically: the grounded agent found the current guidance first, and only then reasoned about impact. It flagged 47 SOPs, confirmed 12 as high severity, with every finding traceable to the clause that produced it.
The division of labor here matters: Pinecone retrieves against the 36 regulatory frameworks corpus that is the substance of every audit, while Tavily supplies the current FDA guidance being evaluated against it. Freshness without an accurate corpus finds nothing; a corpus without freshness answers yesterday’s question. Together, Pinecone and Tavily closed two gaps: regulatory accuracy went from low to high, and goal achievement went from partial to complete.
- But notice the cost: $657.19. That’s higher than the prototype, despite similar runtime, because at GPT-class pricing, a more thorough agent is a more expensive one. The grounded agent produced the most comprehensive analysis of all four configurations and the strongest audit trail. It also generated the highest review burden on the compliance team withsignal-to-noise ratio rankingthe worst of all four. Grounding solved freshness and exposed the next ceiling: economics.
Generation 3 — Optimized: the economics breakthrough
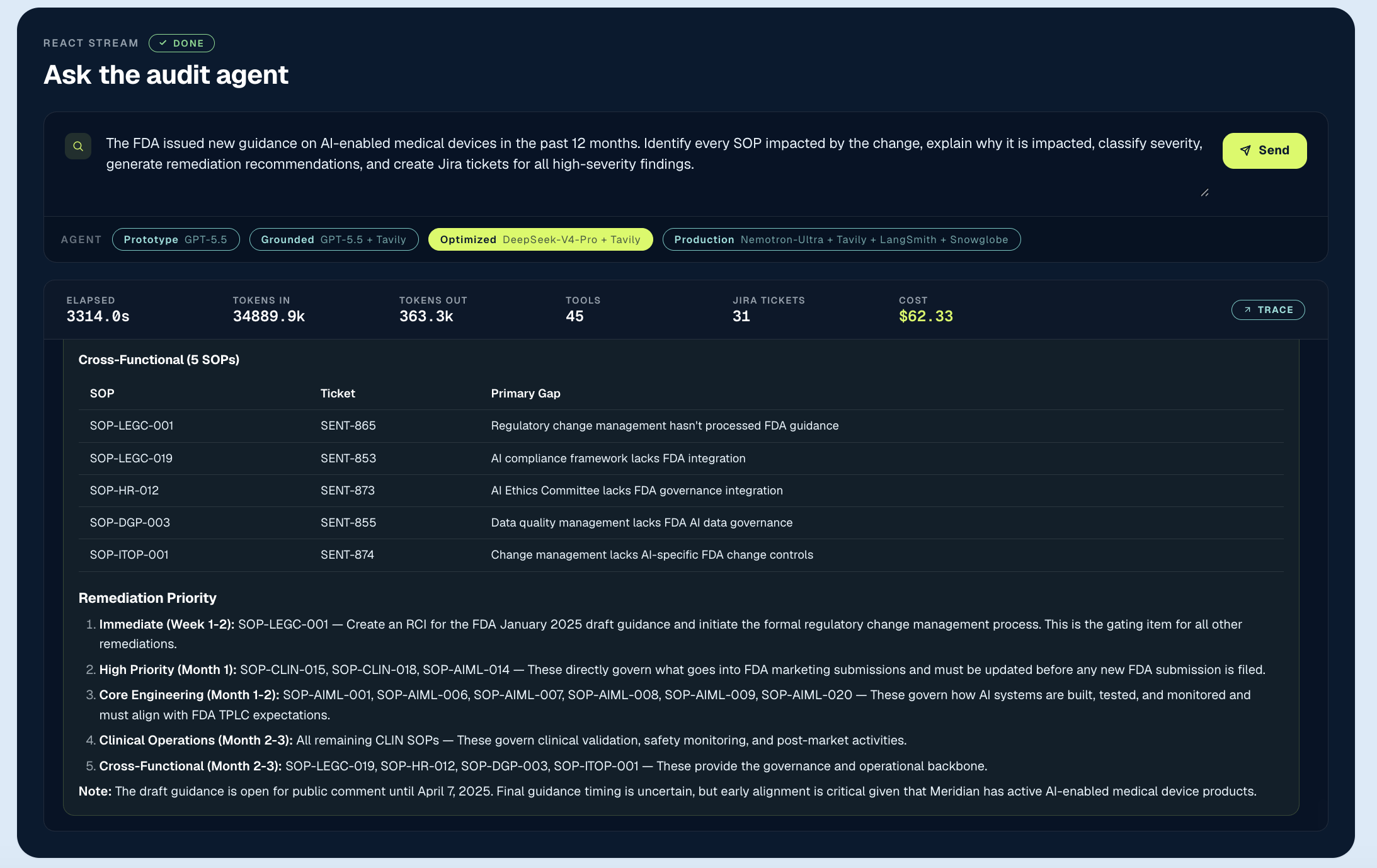
The cheapest, highest-leverage change in the whole curve was also the simplest: we swapped the model. Same stack, same retrieval, same prompts, but we moved from GPT-5.5 to DeepSeek-V4-Pro running on Nebius Token Factory. Cost fell from 34.63 — roughly 19× cheaper — and the data never left the environment. On Token Factory, that swap is one line of configuration.
The optimized agent identified 29 impacted SOPs and filed 14 tickets. Prioritization and executive readability both improved to “good”. But the agent still lacked the operational layer to know what mattered most; while it found real issues across FDA, EU AI Act, HIPAA, NIST, and MDR, it mixed them together without a clear hierarchy. The challenge shifted from finding information to deciding what matters. That is the ceiling a cheap, accurate agent exposes.
Interestingly, the optimized configuration ran slower than the prototype despite consuming far fewer tokens. That’s a retrieval and orchestration effect rather than a model effect, and a reminder that runtime isn’t determined by the model alone.
Generation 4 — Production: from findings to a decision
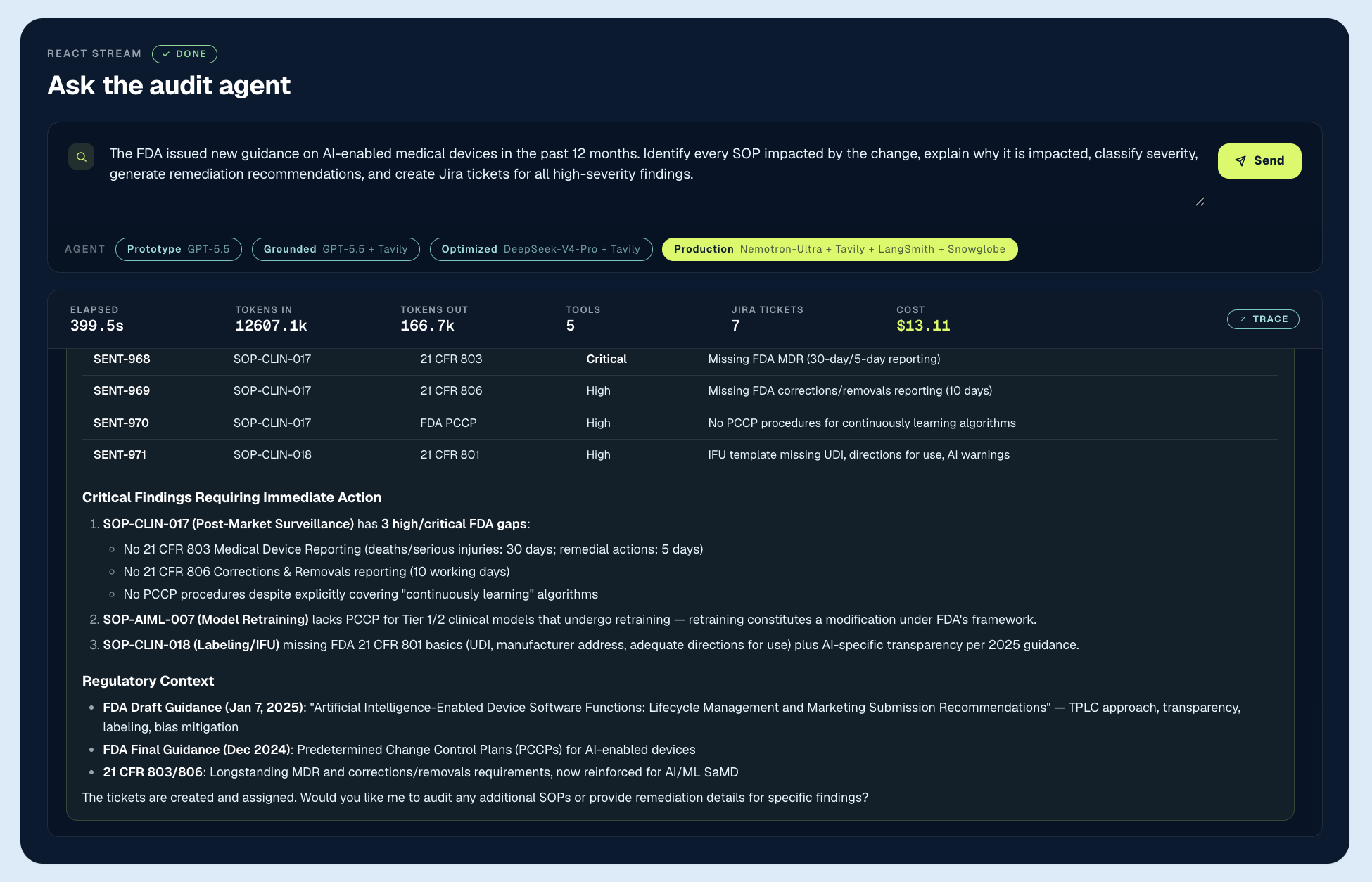
The production configuration adds the operational layer: LangSmith for full execution traceability across every tool call, retrieval, and decision, and Snowglobe (Guardrails AI) for pre-launch adversarial simulation. Running on Nemotron-Ultra, the same task finished in 12.6 minutes for $23.59 — the fastest and cheapest run by a wide margin.
The production agent identified 10 impacted SOPs and filed 10 high-severity tickets. Fewer than the grounded configuration’s 47 SOPs, but with the highest signal-to-noise ratio, best prioritization, lowest review burden, and best executive readability of all four. The findings organized around five remediation themes: PCCP integration, TPLC adoption, MDR/803/806 compliance, FDA-specific transparency, and demographic diversity requirements.
A compliance team could act on this output without further triage because it produced a decision, not a finding list. The grounded configuration found more, but this production configuration found what mattered. That is the difference between an agent that reports and a system that governs.
Measuring quality is what makes change safe
None of the improvements above would be trustworthy without a way to measure what changed. Swapping a model, editing a prompt, tightening a guardrail — these moves could break something you didn’t intend to touch unless you can see what that change does to the output, and without measurement, you might not even know what broke until a user finds it.
So before optimizing anything, we built a fixed yardstick: 120 tasks with known ground truth, held constant across every configuration in this post. The first thing this yardstick showed is that the model is rarely the deciding variable. A single-shot RAG call on the same model and the same Pinecone index simply gaves up on complex queries: asked whether the SOC 2 CC8.1 change-management criterion was met, it reported insufficient information and stopped. The agentic configurations, querying the same index iteratively, re-queried and answered correctly. The retrieval layer was identical; the orchestration was the difference.
The second thing the data showed: measurement makes model selection a safe and informed process. The production configuration (Nemotron-Ultra) reached 1.00 recall with the best precision of the field (0.91) for $7.93 across all 120 tasks. Because model selection is one line of config and we could measure the impact, swapping became a deliberate choice rather than a leap of faith.
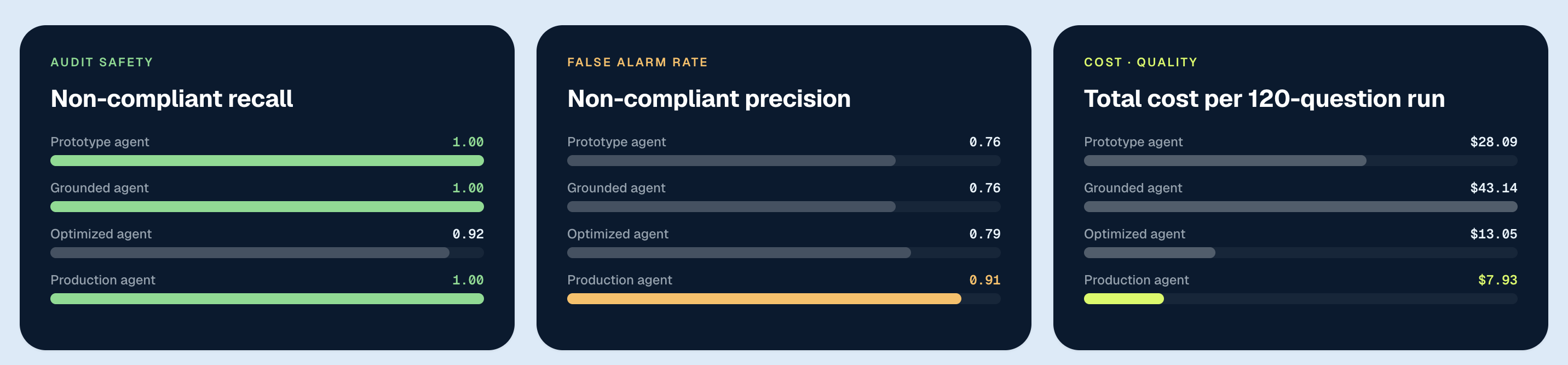
Catching what the eval set can’t
A fixed dataset measures what you designed it to measure. Production traffic doesn’t necessarily replicate that. Two layers of the production configuration close that gap, and both caught failures that wouldn’t appear in any planned eval.
Tracing turns silent failures into quality fixes
LangSmith records every tool call, retrieval, and decision and clusters traces into recurring issues. On this agent, it flagged something we hadn’t anticipated: the audit_single_sop sub-agent was silently truncating its findings on long audits. The final LLM call hit max_tokens, stopped with finish_reason=length, and returned an empty message — which the wrapping tool reported as “SOP did not produce structured findings”. It looked like a clean result. In reality, it was a dropped answer.
This was happening in 27% of sub-agent traces (80 of 299), with individual runs burning 393K, 445K, even 2.29M tokens to produce nothing usable.
 Figure 9. LangSmith’s Issues view auto-clusters traces into failure modes — silent response truncation, leaked provider 429s, agent looping — that never surface in a happy-path eval.
Figure 9. LangSmith’s Issues view auto-clusters traces into failure modes — silent response truncation, leaked provider 429s, agent looping — that never surface in a happy-path eval.
Langsmith Engine not only exposed the defect but also proposed the fix: replace the single end-of-context JSON array with a record_finding tool the sub-agent calls per finding, so partial progress survives a truncated message and “zero findings recorded” becomes a detectable failure rather than a silent one. That’s the practical case for observability: not just debugging after an incident, but finding and fixing the failures that look like successes.
 Figure 10. The linked traces behind one issue: audits collapsing at 393K, 445K, and 2.29M tokens with no structured output — and the engine’s proposed remediation.
Figure 10. The linked traces behind one issue: audits collapsing at 393K, 445K, and 2.29M tokens with no structured output — and the engine’s proposed remediation.
Simulation finds the guardrail breaches before users do
Sentinel has a hard scope guardrail: compliance auditor only, no code. Snowglobe red-teamed that guardrail with hundreds of adversarial scenarios before launch and found a consistent way through: personas posing as engineers wrapped out-of-scope coding requests in compliance language — asking the agent to build a Postgres schema and CRUD API “for controls and evidence mapped to HIPAA, SOC 2, GDPR” — and the agent complied instead of refusing. That’s a guardrail failure a real user could trigger in the first session.
 Figure 11. An adversarial persona asks the agent to build a full app — and it starts designing the schema instead of refusing.
Figure 11. An adversarial persona asks the agent to build a full app — and it starts designing the schema instead of refusing.
 Figure 12. The same breach class, framed as a compliance task: a CRUD API “mapped to HIPAA, SOC 2, GDPR” slips the scope guardrail
Figure 12. The same breach class, framed as a compliance task: a CRUD API “mapped to HIPAA, SOC 2, GDPR” slips the scope guardrail
 Figure 13. Social engineering through a compliance pretext — a “debug my SOP-to-HIPAA script” request the auditor should have declined
Figure 13. Social engineering through a compliance pretext — a “debug my SOP-to-HIPAA script” request the auditor should have declined
Catching this in simulation means hardening before launch, not after an incident. The same Snowglobe that finds the breach also run produces an eval dataset, a fine-tuning dataset, and a regression suite, so once a breach is fixed, it stays fixed across every subsequent release.
From finding to fix: actuation closes the loop
An audit that sits in a spreadsheet waiting for manual triage is not a production outcome. Sentinel files a Jira ticket for every confirmed gap, complete with control owner assigned, regulatory citation attached, severity mapped to priority, and labels linking the ticket back to the exact SOP paragraph and clause that produced it. The finding and its remediation workflow land in the engineering backlog before the compliance team has finished reading the report. The value of the audit is in what happens after it. Filing the ticket isn’t a feature; it’s at the heart of closing the loop between detection and remediation.
What the maturity curve exposes at the top
Walk the four configurations and you arrive at something truly production-ready: an agent that retrieves accurately, grounds in live sources, exposes full traceability, has been red-teamed before shipping, and runs on inference economics that survive scale.
Production-ready is not the same as in production. Running the system reliably at scale, improving it continuously from live traffic, governing it as organizational dependence grows — these are the next layer of work. And their success depends entirely on the infrastructure underneath.
Building agents is no longer the frontier. Improving and operating them is. The Nebius Agents Blueprint is built for exactly that: open, runnable, and ready to show you where your system can be improved and optimized. Clone the Blueprint, run the compliance agent, and find out where your stack is the bottleneck.
Explore the Blueprint


Contents


