
MLPerf® Training 6.0: Leading NVIDIA HGX B300 and competitive NVIDIA GB300 NVL72 results on NVIDIA Blackwell Ultra systems
MLPerf® Training 6.0: Leading NVIDIA HGX B300 and competitive NVIDIA GB300 NVL72 results on NVIDIA Blackwell Ultra systems
Independently verified results mean more than any claim we could make ourselves. That’s why we submit to MLPerf® every round.
For MLPerf® Training 6.0, we submitted six configurations powered by NVIDIA Blackwell Ultra systems: NVIDIA HGX B300 and NVIDIA GB300 NVL72. [1]-[12] Nebius posted the #1 single-node NVIDIA HGX B300 times for Llama-3.1-8B and GPT-OSS 20B pre-training. Read on for the full results and methodology.
This round continues our commitment to transparency and collaboration with the MLCommons® community and gives customers a verified view of Nebius AI Cloud performance on demanding GenAI training workloads. Our submission demonstrates the performance and efficiency of the top-notch GPUs that empower Nebius to benefit customers training the world’s most advanced models.
Engineered for GenAI workloads
Designed from the ground up for AI, Nebius’ infrastructure combines hardware innovation and software-level optimization, ensuring reproducible efficiency for modern AI workloads spanning multimodal training and LLM fine-tuning tasks.
Each layer of our AI cloud stack is carefully tuned to achieve consistent GPU utilization and minimize infrastructure overhead, from custom-designed servers to hypervisor-level optimizations that deliver bare-metal-class performance on virtual instances.
For MLPerf® Training 6.0, Nebius focused on foundation model training across different cluster sizes and evaluated performance on three workloads:
-
Llama-3.1-8B — large language model pre-training
-
FLUX.1 — image generation model pre-training
-
GPT-OSS 20B — MoE large language model pre-training
The HGX B300 system was tested on a single node (8 GPUs), four nodes (32 GPUs), and eight nodes (64 GPUs). The GB300 NVL72 platform was evaluated on two nodes (8 GPUs total), eight nodes (32 GPUs total), and 18 nodes (72 GPUs total). [1]-[12]
Leading single-node results and competitive multi-node performance
In this MLPerf® Training 6.0 submission, Nebius benchmarked two NVIDIA Blackwell Ultra platforms across six node-based configurations. Training time is reported in minutes, where lower values indicate better performance. Green highlights indicate the fastest time among all submitters using the same GPU type and comparable GPU count.
In this round, Nebius benchmarked:
-
NVIDIA HGX B300: single node (8 GPUs), four nodes (32 GPUs), and eight nodes (64 GPUs)
-
NVIDIA GB300 NVL72: two nodes (8 GPUs total), eight nodes (32 GPUs total), and 18 nodes (72 GPUs total)
Table 1. NVIDIA HGX B300 results (closed division, minutes)
All results: MLPerf® v6.0 Training, closed division. Training time in minutes (lower is better). Fastest result at each GPU count and GPU type is shown for reference in section text.
HGX B300 delivers leading single-node results
On the single-node HGX B300 configuration (8 GPUs), Nebius achieved the fastest HGX B300 result for two of the three benchmarks submitted:
-
Llama-3.1-8B: 72.01 minutes — fastest among 11 HGX B300 submissions in the closed division [1]
-
GPT-OSS 20B: 83.62 minutes — fastest among 12 HGX B300 submissions in the closed division [9]
These results show strong single-server efficiency on HGX B300 and reinforce the value of careful infrastructure tuning for performance-intensive foundation model training.
Nebius also submitted multi-node HGX B300 results on four nodes (32 GPUs) and eight nodes (64 GPUs). On the eight-node configuration, HGX B300 completed Llama-3.1-8B in 14.42 minutes, FLUX.1 in 46.71 minutes, and GPT-OSS 20B in 23.48 minutes, extending the platform’s coverage to larger training runs.
GB300 NVL72 performs strongly at rack scale
Nebius’ submissions on GB300 NVL72 demonstrated strong competitive performance across all three benchmarks on the 18-node configuration (72 GPUs total). Results were within 3.1% of the fastest GB300 NVL72 submission in every case:
-
Llama-3.1-8B: 11.87 minutes — within 2.5% of the fastest GB300 NVL72 result (11.59 min) [4]
-
FLUX.1: 37.65 minutes — within 3.1% of the fastest GB300 NVL72 result (36.54 min) [8]
-
GPT-OSS 20B: 18.20 minutes — within 0.8% of the fastest GB300 NVL72 result (18.05 min) [12]
On the eight-node GB300 NVL72 configuration (32 GPUs total), Nebius achieved the second-fastest FLUX.1 result among GB300 NVL72 submitters with 65.85 minutes, within 1.3% of the top result of 65.03 minutes. [7]
These results place Nebius’ deployment of GB300 NVL72 in the leading performance range on equivalent hardware for the submitted benchmarks.
GB300 NVL72 delivers faster training than HGX B300 at equivalent GPU counts
Nebius submitted results for both platforms at matching GPU counts, 8 GPUs and 32 GPUs, enabling a direct comparison across generations on the same workloads.
At 8 GPUs, GB300 NVL72 completed Llama-3.1-8B training in 64.35 minutes [3] compared to 72.01 minutes on HGX B300 [1], approximately 12% faster. GPT-OSS 20B showed a similar improvement, with GB300 NVL72 finishing in 75.26 minutes [11] versus 83.62 minutes on HGX B300 [9], approximately 11% faster.
At 32 GPUs, GB300 NVL72 completed FLUX.1 training in 65.85 minutes [7] compared to 77.48 minutes on HGX B300 [5], approximately 18% faster.
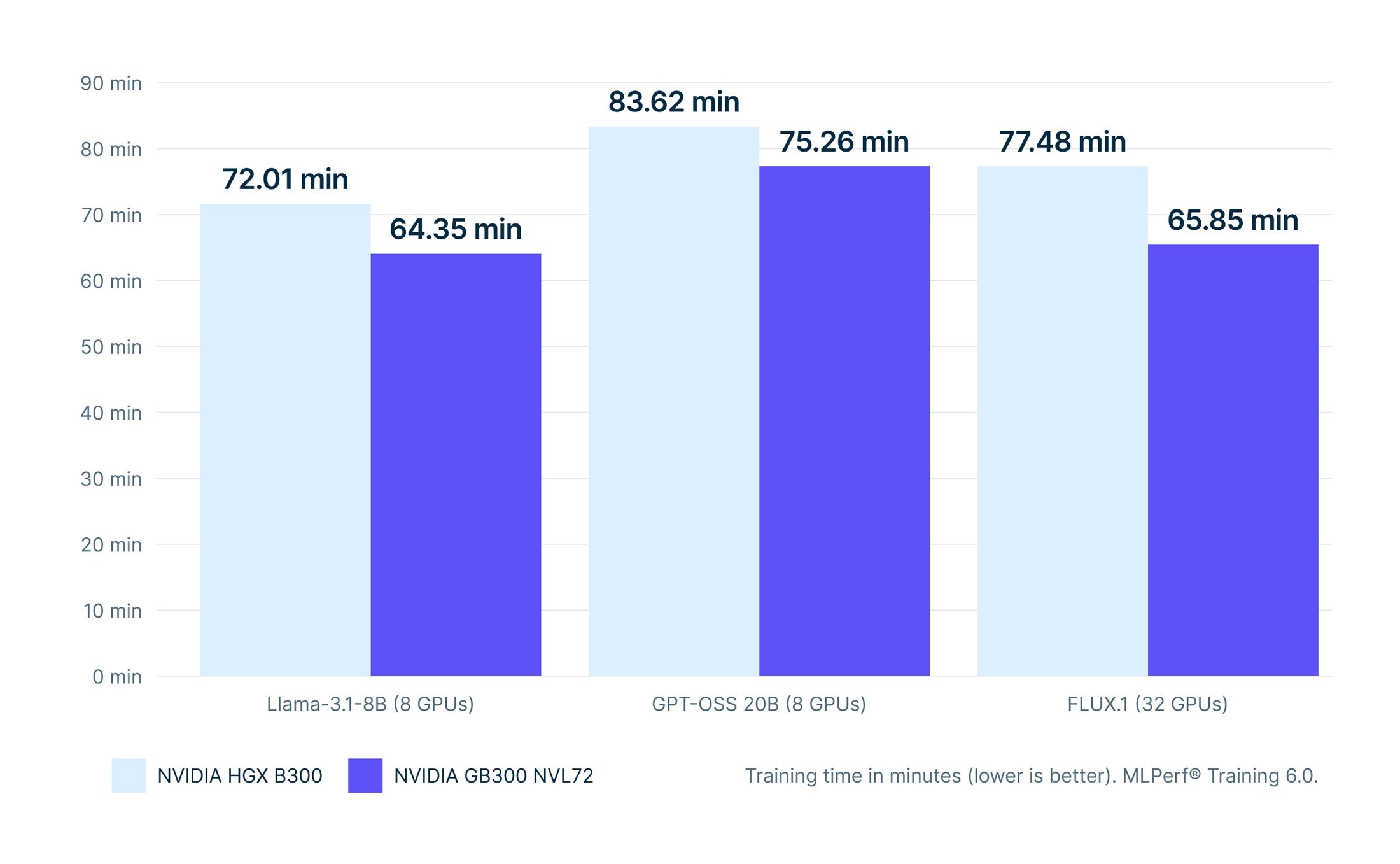
Across all three comparisons, GB300 NVL72 delivered lower training times than HGX B300 at the same GPU count, reflecting the performance advantages of the advanced GB300 NVL72 rack-scale systems.
Conclusion
Our MLPerf® Training 6.0 submission reinforces Nebius’s position in AI training performance across both NVIDIA HGX B300 and GB300 NVL72 systems. The NVIDIA HGX B300 results establish Nebius as the fastest single-node HGX B300 provider for Llama-3.1-8B and GPT-OSS 20B pre-training in this benchmark round. The GB300 NVL72 results show competitive 72-GPU performance across all three benchmarks evaluated.
As a Reference Platform NVIDIA Cloud Partner, Nebius works closely with NVIDIA to ensure that these systems operate at their full potential, aligned to NVIDIA reference designs, to achieve optimal utilization and stability in large-scale distributed training environments.
Our customers benefit from achieving exceptionally high GPU utilization in the cloud, which accelerates research and development, and creates new breakthroughs in language, vision, and multimodal AI. From building large-scale models to deploying novel products, Nebius empowers innovators to turn ideas into tangible advances in artificial intelligence.
To learn how we can support your AI projects at scale, contact us.
References
- MLPerf® v6.0 Training Closed Llama3.1-8b, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0023. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed Llama3.1-8b, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0025. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed Llama3.1-8b, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0027. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed Llama3.1-8b, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0026. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed Flux1, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0024. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed Flux1, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0025. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed Flux1, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0028. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed Flux1, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0026. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed GPT-OSS-20b, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0023. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed GPT-OSS-20b, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0025. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed GPT-OSS-20b, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0027. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵
- MLPerf® v6.0 Training Closed GPT-OSS-20b, June 16, 2026, Retrieved from mlcommons.org/benchmarks/training/, entry 6.0-0026. Result verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information. ↵



